我个人对实验五的全部实现代码在:Stanford_CS336_Assignment5_2025Spring
Assignment5的目的是让我们对Qwen 2.5 Math 1.5B这个模型进行SFT以及RL训练。
利用vLLM进行模型推理
主要目的是熟悉vllm的部分接口,通过vllm这个原生推理加速框架来对llm进行快速的inference操作。同时为后面SFT训练的时候使用vLLM框架做推理测试提供一个可复用的接口。
1 | from transformers import AutoTokenizer, AutoModelForCausalLM |
实现SFT微调Qwen 2.5 Math 1.5B
对于给定的输入 prompt 和 output 文本对,利用预训练的 tokenizer 分别对它们进行编码,然后将他们concat在一起作为训练的输入序列。
由于每个输入的长度不一,这里采用了朴素的找到最长的输入序列,将其余序列给padding到和它相同长度的方法进行填充。同时生成对应的mask,用来判别哪些是输入以及padding的token,哪些是模型最终输出的token。
1 | def tokenize_prompt_and_output( |
接下来需要知道每一个token的条件概率。通过model的前向传播,我们可以得到每一个token的logits,然后通过log_softmax可以得到每一个token的条件概率。最后通过gather以及labels就可以得到每一个token的条件概率。
1 | def get_response_log_probs( |
在得到对应token的条件概率之后,就可以来进行训练了。在这里得到的log_probs是整个序列的条件概率,因此需要使用之前处理的response_mask来过滤掉prompt和padding的token。由于大模型在微调的时候,通常是使用cross-entropy loss,因此这里计算的是负的log_probs。最后,为了得到每个batch的平均loss,需要除以batchsize和gradient_accumulation_steps。
1 | def masked_normalize( |
在得到了这些辅助函数之后就可以编写微调代码了,代码在sft_qwen_math.py
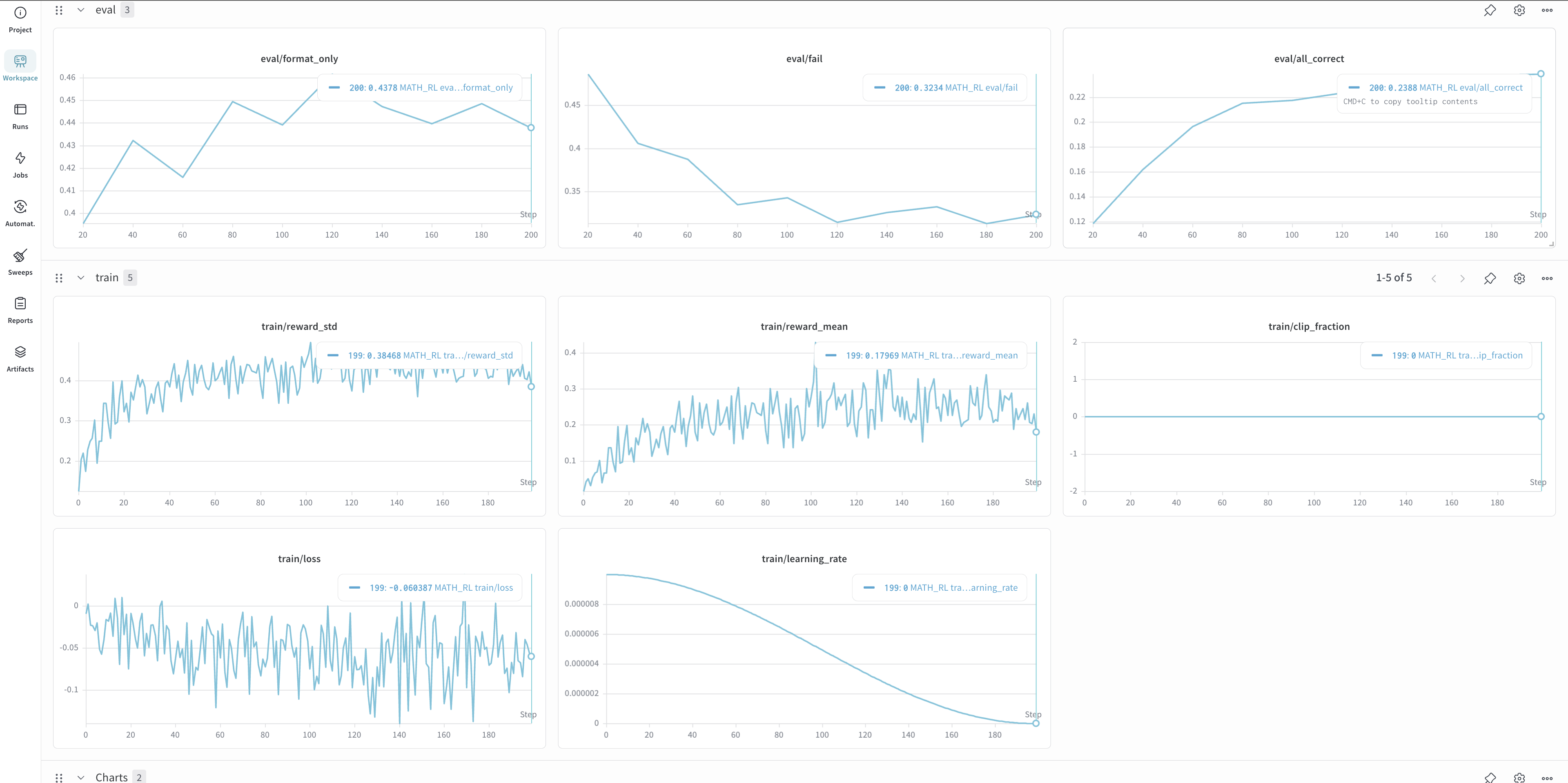
实验结果也是符合assignment的预期的。在使用全部的sft.jsonl数据进行微调的时候,在validation.jsonl上能够达到超过15%的准确率:
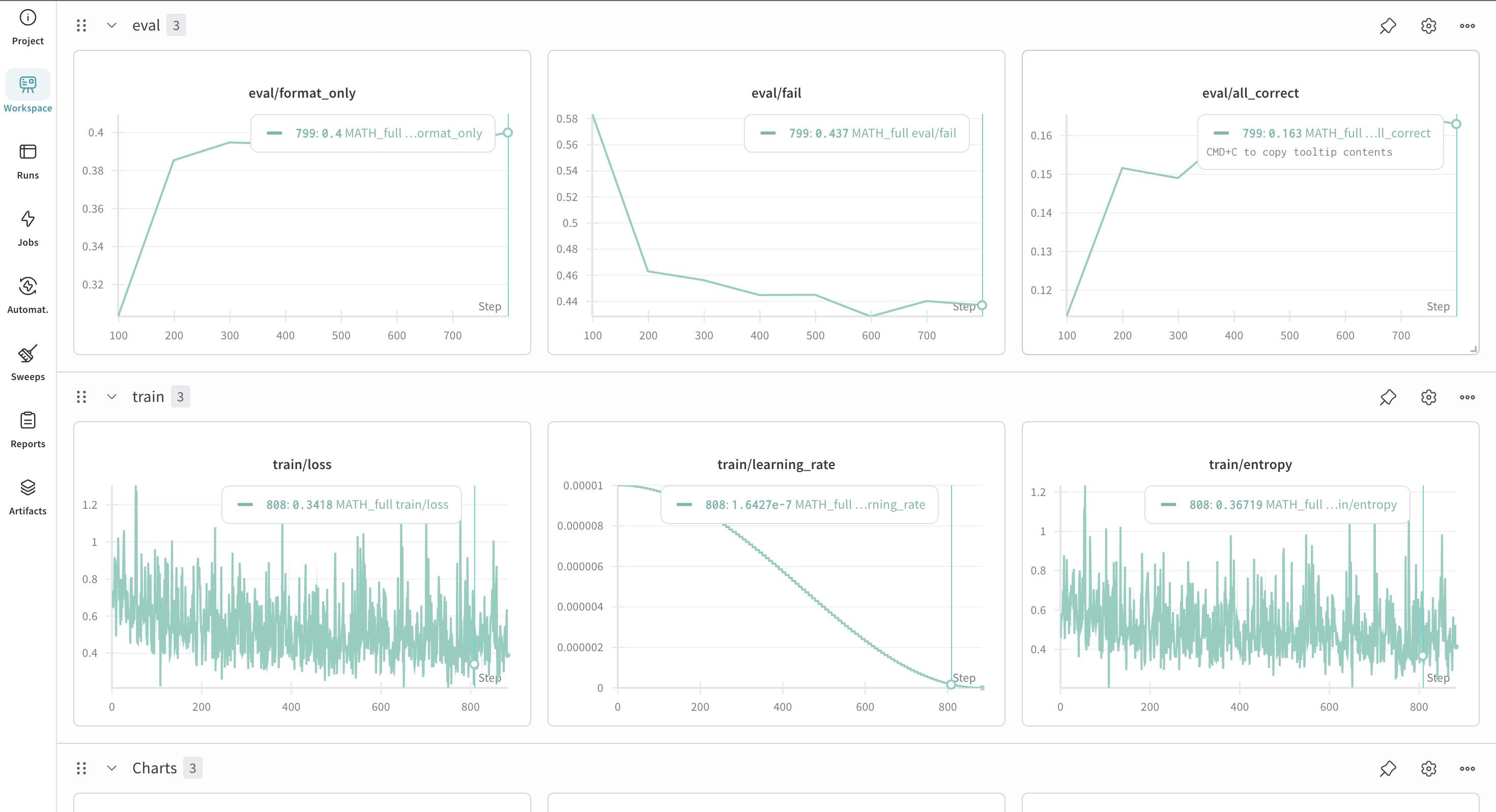
同时按照assignment里面的要求,利用提供的r1 reward对正确的数据进行了过滤,利用过滤后的数据进行训练可以明显看出在验证集上的效果有提升:
专家迭代
专家迭代(Expert Iteration)是一种利用模型性能自举进行SFT的手段。
模型初始化:
将当前策略模型 $\pi_{\theta}$ 设定为初始模型 $\pi_{\theta_{\text{init}}}$。迭代循环 (执行
n_ei_steps次):- 采样问题:从总任务集 $\mathcal{D}$ 中随机抽取一批问题 $\mathcal{D}_b$。
- 备份模型:将当前的策略模型记录为旧模型 $\pi_{\theta_{\text{old}}}$,作为本轮生成数据的基准。
- 生成样本 (Sampling):针对 $\mathcal{D}b$ 中的每个问题 $q$,利用旧模型采样生成 $G$ 个不同的回答 ${o^{(i)}}{i=1}^G$。
- 计算奖励 (Scoring):运行奖励函数 $R(q, o^{(i)})$。如果回答正确,则奖励 $r^{(i)} > 0$(通常为 1);如果错误,则为 0。
- 构建微调数据集 (Filtering):过滤掉所有错误的回答(即 $r^{(i)} = 0$ 的样本),仅保留正确的问题-回答对,形成一个有监督微调数据集 $\mathcal{D}_{\text{sft}}$。
- 策略更新 (SFT):使用 $\mathcal{D}{\text{sft}}$ 对当前模型 $\pi{\theta}$ 进行有监督微调(Supervised Fine-Tuning)。这一步是让模型向自己产生的“正确答案”学习。
输出:
迭代结束,输出优化后的策略模型 $\pi_{\theta}$。
通过专家迭代采样以及对应的奖励函数来生成用来自举的数据:
1 | def expert_iteration(policy_model: LLM, reward_fn: Callable, sampling_params: SamplingParams, prompts: List[str], groundtruths: List[str], ei_data_save_path: str = "/root/yjx/assignment5-alignment/data/MATH/"): |
本质上就是使用模型自己生成的数据进行微调。通过这样的策略能够让模型从自我生成的数据中进行学习,从而提升模型的效果。微调的代码在ei_sft_qwen_math.py
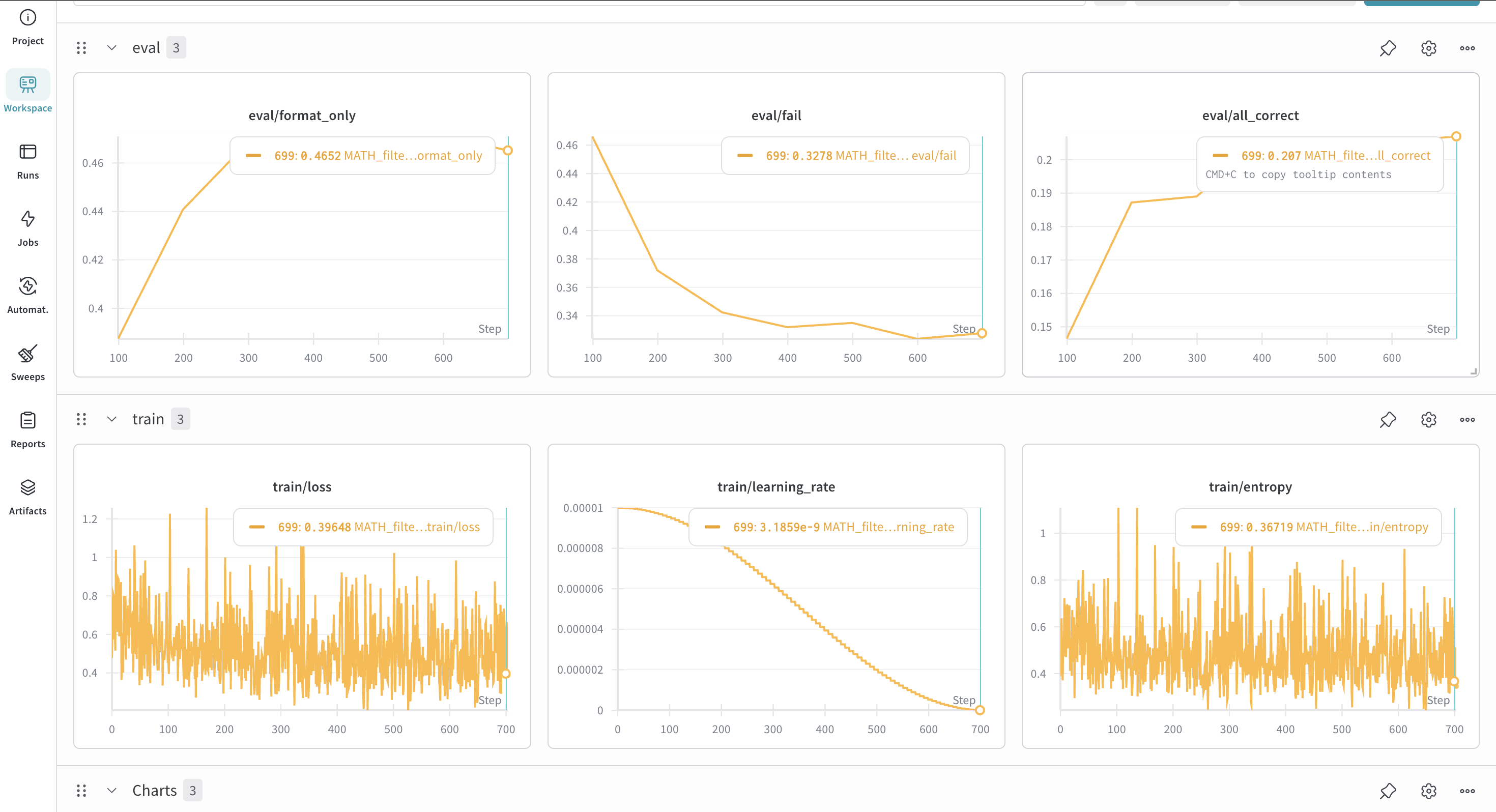
训练曲线如下图所示,可以明显的看出,经过自举训练的模型效果显著的要高于仅仅用普通SFT的模型:
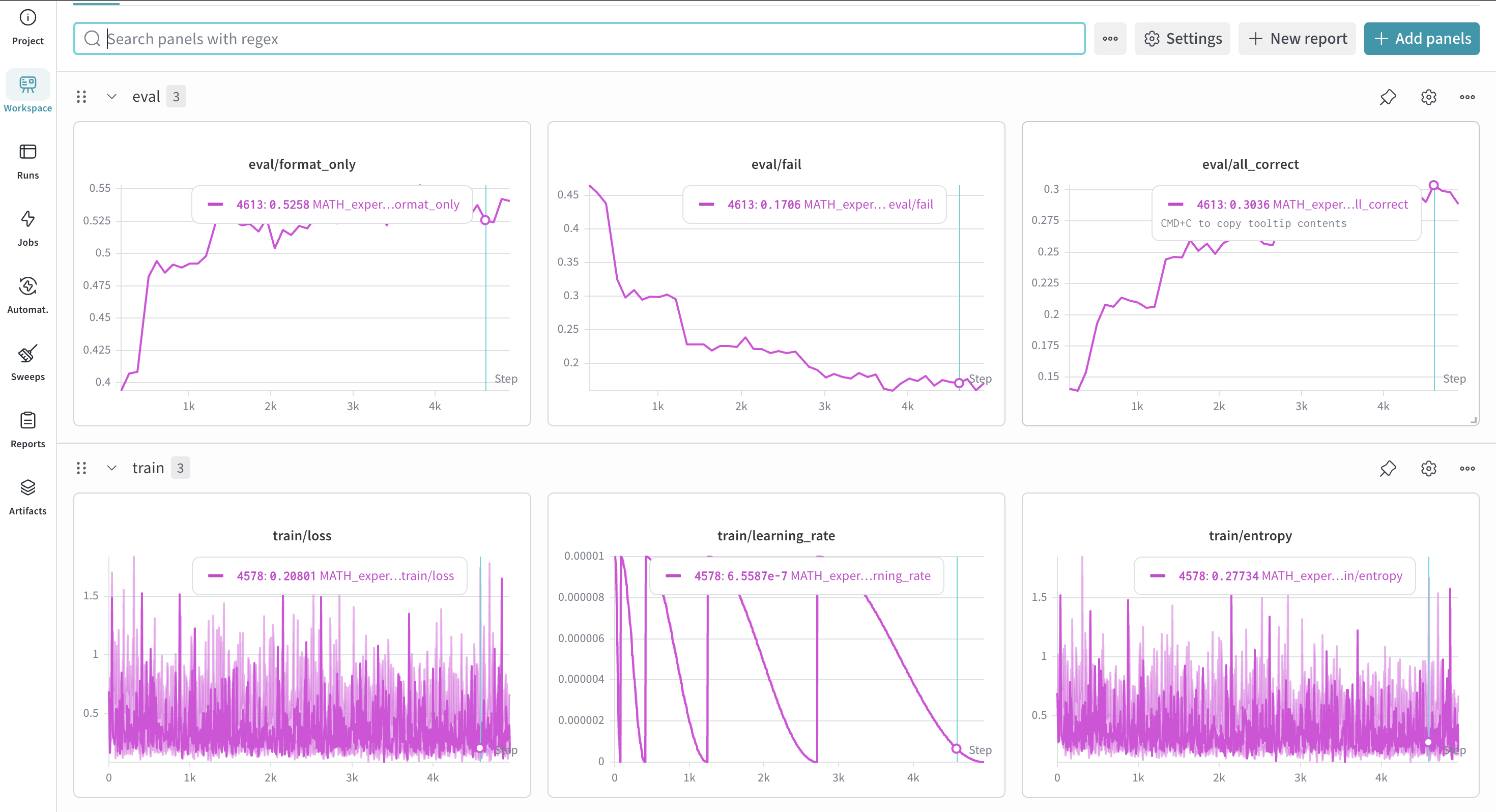
强化学习
这里使用了GRPO作为这个实验的RL训练方式。GRPO的优势在于他去掉了价值模型,即Critic模型,而是直接使用组内相对优势来更新策略模型。对于强化学习的原理在这里不进行赘述,在训练过程中需要注意的点在于,