例行总结过去一年,还是和去年一样,从实习,学业以及生活三个方面来写点流水账。
实习
在西门子实习到了今年年初的四月份,由于我自己不想干了,同时毕业设计也即将ddl,顺便享受一下剩下的大学生活,就离职了。实习的主要工作就是做了一个基于 self-supervised 的方法来检测 西门子自己PCB的缺陷的工作。我大概是把所有的代码给跑通了,有了一个初步的结果。
对于输入的图片,上面会有8块相同的PCB板子。对于这些PCB板子,首先采用传统CV图像识别的方式,根据模版图片识别出具体八块PCB。由于我们使用的是4K的摄像头,因此每一块PCB的分辨率非常的高,直接输入给模型做推理或者训练的话会非常的大。
想到一张方法就是先对模型进行分块处理,对于每一个输入的PCB板子,在训练阶段,把它分成128*128的小块,同时对于每一个小块,记录对应的位置,方便后续加入位置编码,然后打乱交给后续的图像编码器;在推理阶段,顺序的把PCB板子每一块给切割成对应的小块,同时记录位置。
得到128*128的小块之后,采用利用经过预训练的图像Encoder得到图像的编码,这里有多种选择方式,例如 ResNet, SwinUnet, SwinTransformer 等等模型可以选择。在
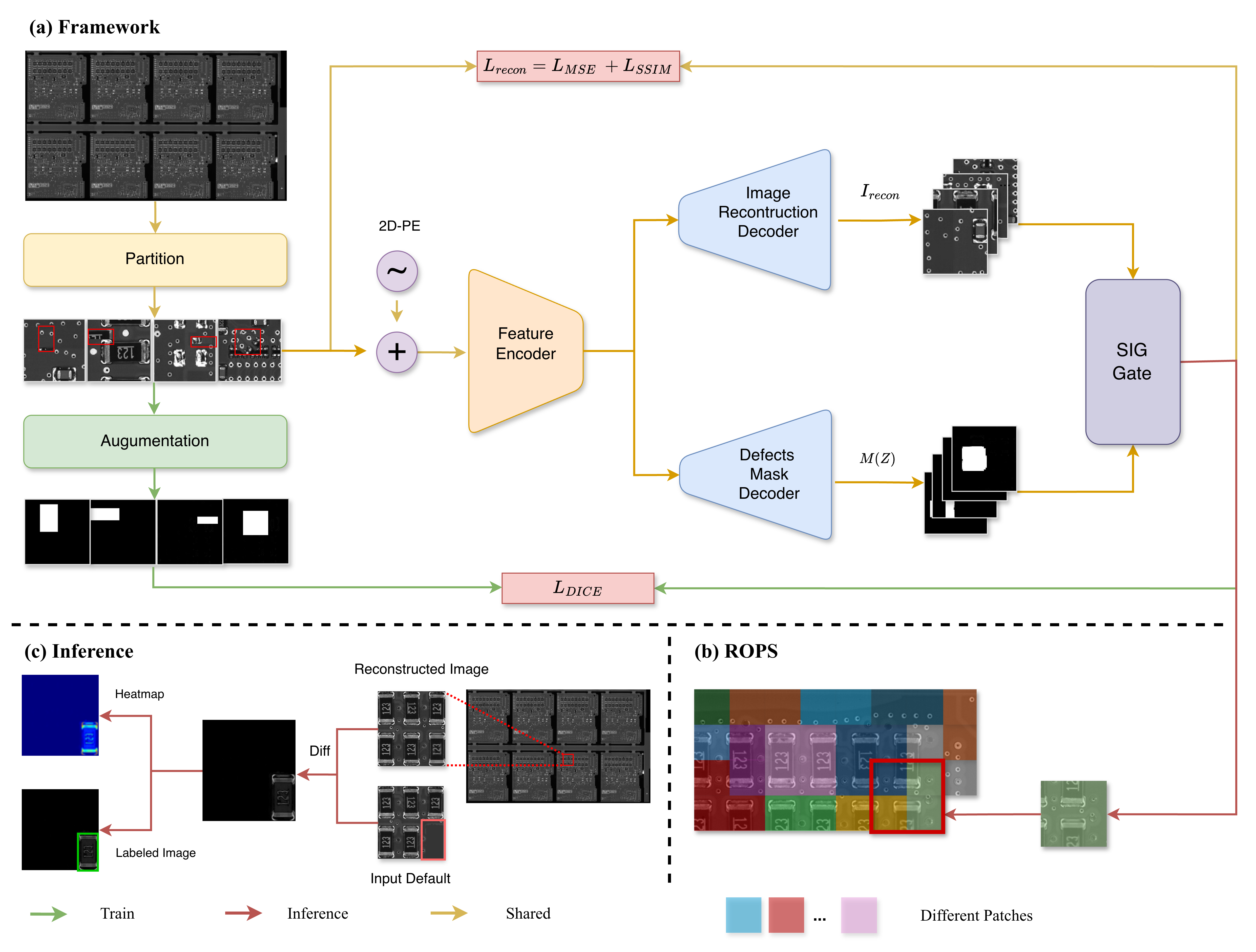
整体算法流程图
学业
TBD
生活
TBD
写在最后
TBD